

Нескучные исследования
Каждый год студенты третьего курса специализации «Исследования в коммуникациях» работают над итоговыми групповыми проектами в рамках дисциплины «Инструменты и методы в коммуникационных исследованиях». В прошлом учебном году под руководством преподавателя Департамента Кирилла Чмеля студенты провели более 10 исследований. Получившиеся проекты показывают, что в исследованиях можно самовыражаться и проявлять фантазию, при этом получая полезные и интересные результаты.

Проекты третьекурсников показывают, что в исследованиях есть место творчеству и креативу. Так, ребята изучали тексты хип-хоп исполнителей, отношение к пандемии в разных районах Москвы и регионах России. Мы узнали у ребят, почему они выбрали такие темы, какой инструментарий они использовали и к каким результатам пришли.
Я не слышу себя под автотюном
Команда: Балашова Анна, Григорьева Анастасия, Федосеева Алина
Наш проект иронично называется «Я не слышу себя под автотюном». Его тема – анализ текстов старой и новой школы рэпа, а также генерация собственного. Мы выбрали ее абсолютно случайно! Нашли смешной мем про эти два направления и нам стало интересно посмотреть, чем отличаются тексты старой и новой школы и сможем ли мы сгенерировать собственный на основе уже существующих
Исследовательский процесс
Шаг 1. Составление базы данных
Было отобрано по 100 представителей старой и новой школы. С сайта Genius ребята выгрузили тексты их песен и объединили их в два txt файла.
Шаг 2. Определение наиболее часто встречающихся слов у двух направлений
Для этого была проведена кластеризация: студенты проверяли, можно ли отнести тексты к двум кластерам (группам), как это было изначально. Далее ребята провели тематическое моделирование: они определяли темы и их связи в двух общих массивах текстов – для этого они применили метод латентного распределения Дирихле.
Словарик исследователя:
Латентное распределение Дирихле – модель, которая помогает объяснить причины сходства разных частей данных. Например, сходства текстов представителей новой и старой школы хип-хопа.
Шаг 3. «Написание» собственного текста
Для этого студентам пригодилась скрытая марковская модель. Это работает так: машина обучается на запоминание стоящих рядом с определенным словом слов, ей задается длина текста и отправное значение. Готово – машина выдает готовый текст!
Словарик исследователя:
Скрытая марковская модель – это модель, которая может на основе заданных параметров разгадать неизвестные параметры. Студенты РиСО таким образом “научили” ее писать рэп на основе уже существующих текстов. В мире эта модель получила широкое распространение в области распознавания речи, письма, движений и биоинформатике.
Результаты
Студенты определили, чем исполнители новой школы отличаются от представителей олдскула: они больше говорят о деньгах, своих достижениях. Тем не менее, в творчестве новой школы отражены традиции, заложенные авторами старой школы, а также присутствует романтическая тема. К примеру, представители нью-скул упоминают Бруклин – район Нью-Йорка, который раньше считался «чёрным» и криминальным – об этой местности начали говорить ещё исполнители старой школы. И хотя среди тем исполнителей присутствуют сходства и различия, можно утверждать, что в хип-хоп музыке существует определенный фольклор: устойчивые темы, выражения, которые свойственны всем исполнителям данного жанра.
Эмоционльная карта районов Москвы
Команда: Васильева Евгения, Игнатьева Елизавета
По мнению ребят, районные сообщества ВКонтакте, такие как «Подслушано Люблино», «Мой Даниловский», всегда были отражением наиболее волнующих для населения тем, площадкой для обсуждения как районных, так и личных проблем. Поскольку с введением режима самоизоляции горожане стали значительно больше времени проводить онлайн, и, соответственно, чаще выражать свое мнение в социальных сетях, студентам было интересно изучить эти онлайн-сообщества.
Мы решили проанализировать пользовательский контент на таких публичных страницах: выявить тональность сообщений подписчиков и создать интерактивную эмоциональную карту Москвы. Эта карта должна отражать, насколько «позитивным» или «негативным» является каждый из районов столицы в соответствии с эмоциональной окраской комментариев пользователей в этих сообществах.

Евгения Васильева
студентка 4 курса
Исследовательский процесс
Шаг 1. Сбор данных для анализа
Для исследования были использованы комментарии под постами в районных сообществах Москвы за временной период с 3 марта по 3 мая 2020-го года, анализ проводился с применением языка программирования Python 3.0. Студенты сначала выгрузили, а потом отредактировали тексты 37490 комментариев из 115 публичных страниц, собрав их в отдельную базу.
Шаг 2. Обработка данных
Полученные тексты были загружены в библиотеку под названием Dostoevsky - на получившемся массиве ребята применили предсказательную модель FastTextSocialNetworkModel – так каждому комментарию была присвоена тональность в пределах от -1 до 1 (от самого негативного до самого позитивного соответственно). Средний показатель всех комментариев сообщества и стал выражением тональности района.
Словарик исследователя:
Предсказательная модель FastTextSocialNetworkModel – модель, которая обучена определять тон сообщений в социальных сетях именно на русском языке
Шаг 3. Визуализация
В итоге эти значения были визуализированы на карте районов Москвы с помощью цвета, где светло-голубым были выделены самые “негативные” районы, а темно-сиреневым – «позитивные» (в итоговой карте отсутствует тональность некоторых районов ЦАО, а также района Очаково-Матвеевское и Преображенское, так как в сообществах этих районов отсутствуют комментарии).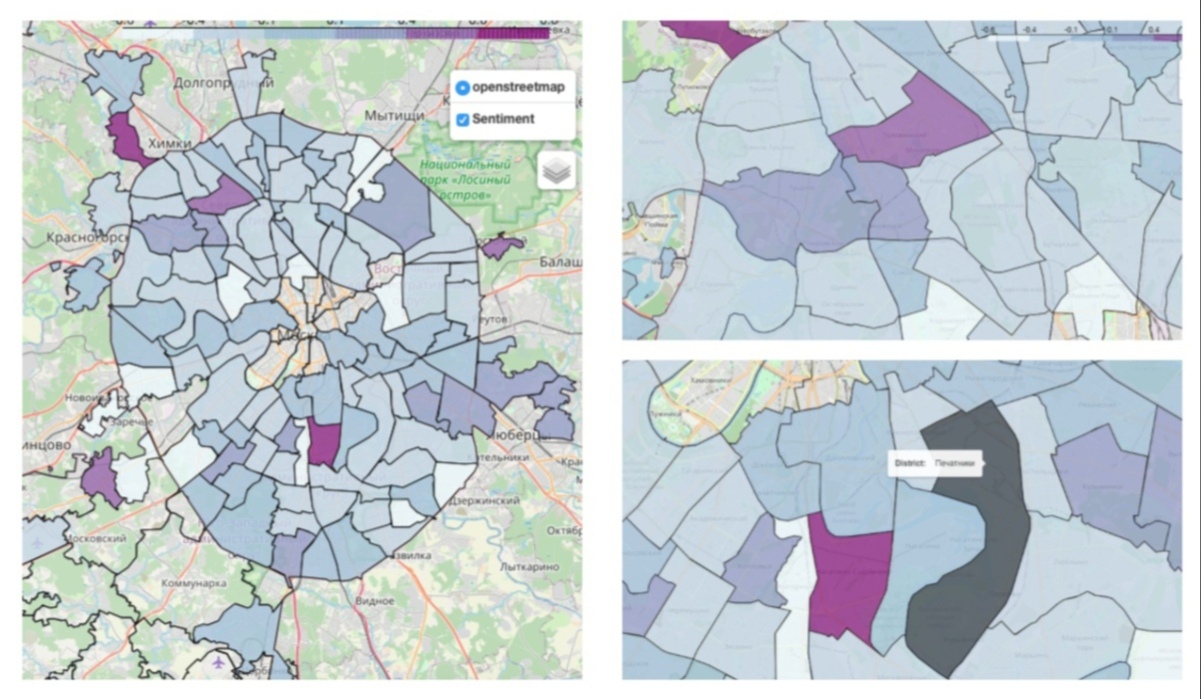
Результаты
Наиболее «позитивными» оказались районы, находящиеся за пределами МКАДа (Куркино, Восточный, Некрасовка, Косино-Ухтоминский), а также районы, прилегающие к городским паркам (например, Головинский, Войковский, Покровское-Стрешнево, Нагатино-Садовники, Выхино-Жулебино). При этом остальная часть Москвы всё же лежит в “негативной” стороне. Почему так вышло? Студенты предполагают, что это можно объяснить как спецификой конкретного района, так и тем, что люди в целом склонны возвращаться и писать о плохом намного чаще, чем о чем-то хорошем. Примерно такая же психология работает у потребителей: они с большей вероятностью напишут отзыв о некачественном товаре, который их крайне разочаровал, но скорее всего не напишут о товаре, который их удовлетворил, так как эмоция разочарования намного сильнее мотивирует оставить отзыв.
Как ВКонтакте вовлекает пользователей в дискурс распространения пандемии
Команда: Шубаев Максим, Андреев Иван, Панькин Никита, Цветков Сергей
COVID-19 быстро распространился по всему миру и перешёл в стадию пандемии – проблема мирового масштаба затронула и Россию. Такие корпорации как Яндекс и Mail.ru Group стараются помочь населению вовлечься в повестку дня и привлечь внимание к проблеме с помощью digital-инструментов. Мы тоже решили внести свою лепту в изучение распространения вируса и способах реагирования пользователей ВК на внезапно появившуюся проблему

Максим Шубаев
студент 4 курса
Исследовательский процесс
Шаг 1. Составление базы данных необходимых пользователей и их характеристик
При помощи API Вконтакте (программного интерфейса, благодаря которому одна программа может взаимодействовать с другой), студенты выгрузили адреса страниц около 300 тысяч пользователей социальной сети. Чтобы выявить отношение людей к пандемии, они выделили определенный атрибут (признак) у каждого пользователя: им стали введенные социальной сетью эмодзи в статусе пользователя, сопровождающиеся текстом.
Используя метод парсинга веб-страниц, студенты извлекли смайлик и сопровождавший его текст и присвоили их каждому пользователю. Они разделили значки на три группы: «серьёзное отношение к пандемии», «нейтральное отношение» и «несерьёзное отношение». После этого ребята категорировали пользователей по региону для того, чтобы выяснить, какой значок чаще встречается в областях.
Словарик исследователя:
Парсинг веб-страниц – метод поиска и сбора необходимой информации из кода страницы
Шаг 2. Сбор статистики по COVID-19 в России по регионам.
Для оценки реальной эпидемиологической обстановки при помощи парсинга сайта «Коронавирусник», на котором имелась актуальная статистика по эпидемиологической обстановке в регионах России, студенты извлекли необходимые показатели заражаемости и смертности.
Шаг 3. Выявление связи между индексом отношения пользователей и коэффициентом заражаемости
После составления полной базы пользователей и скачивания информации с «Коронавирусника», ребята составили индекс отношений каждого региона к пандемии. Затем они составили коэффициент смертности в каждом отдельном регионе и отразили в итоговой таблице полученные результаты: регионы РФ, соответствующие им коэффициенты смертности и отношения к пандемии, а также текст наиболее часто встречающегося у пользователей смайлика.
Шаг 4. Визуализация полученных результатов на интерактивной карте России
При помощи библиотеки Follium студенты внесли координаты столиц каждого региона и создали интерактивную карту.
Словарик исследователя:
Библиотека Follium – библиотека в Python, направленная на визуализацию геоданных или других данных, которые используют местоположение и координаты
Результаты
Результаты исследования показали, что визуальное отображение отношения к пандемии у пользователей ВК не коррелирует с реальной обстановкой в регионе. Иными словами, то, что пользователи писали о коронавирусе в соцсети, не отображало реальную обстановку в их регионе.
С нетерпением ждем новых проектов студентов, а ребятам желаем удачи в проведении исследований для выпускных квалификационных работ!
Алина Федосеева
студентка 4 курса