

В аналитике важна честность перед самим собой
Роман Абрамов окончил бакалавриат и магистратуру факультета экономических наук Высшей Школой Экономики, специализации «Математические методы анализа экономики». Сейчас - руководитель направления «Анализ данных и развитие информационных систем» в Аналитическом центре Москвы. На вебинаре магистерской онлайн программы «Экономический анализ» Роман рассказал студентам и абитуриентам, какие навыки и знания он получил, и как сейчас реализует их на практике. Публикуем расшифровку его выступления. В программе «Экономический анализ» на подготовку таких специалистов нацелен трек по инструментальным методам.

Меня зовут Роман Абрамов, я работаю в Аналитическом центре Москвы и сегодня расскажу про работу аналитика. У моего выступления три цели.
Первое – это поделиться опытом. Я попробовал поставить себя на ваше место как будущих абитуриентов магистратуры, и подумал, что было бы мне интересно и полезно узнать, когда я готовился к поступлению в магистратуру и решал, на какое направление пойти.
Вторая цель - рассказать про Аналитический центр Москвы, чем он занимается. Может быть, кто-то из вас когда-то придет к нам работать.
И третье — я расскажу про Единое хранилище данных – проект, который я создавал и поддержкой которого сейчас занимаюсь. Думаю, он будет полезен, всем тем, кто работает с социально-экономической статистикой.
План встречи: немного расскажу о себе, где учился, чем занимался, какие проекты выполнял; потом про качества, навыки и инструментарий аналитика - мой жизненный опыт, который сформировался на основе тех мест, где я работал. Потом приведу три кейса из своей практики, которые, думаю, будут всем интересны, и в конце я хочу поделиться своим взглядом на образование и ответить на ваши вопросы.

Я окончил бакалавриат Вышки и магистратуру “Математические методы анализа экономики” Вышки в 2010 году. В конце первого курса магистратуры начал работать в госкорпорации Росатом, там я занимался аналитикой и стратегическим консалтингом. Это была небольшая аналитическая компания, стопроцентная дочка Росатома, и мы выполняли различные анализы рынков и построение технико-экономических моделей для оценки эффективности технологий. Было очень интересное время, поскольку вообще в промышленности, в industry, интересно работать, потому что приходится разбираться во многих технических и технологических моментах. Вокруг меня было много кандидатов физ. мат. наук, физиков-ядерщиков, которые меня погружали в тематику, рассказывали различные аспекты, как атомная станция устроена, как идёт работа с ядерным топливом и его переработка. Пример одного из проектов, который мы делали — это разработка стратегии для топливного дивизиона Росатома. Там я непосредственно строил модель рынков ядерного топливного цикла, то есть как в мировой экономике происходит добыча урана, переработка, обогащение и фабрикация топлива, и доставка соответственно в различные реакторы. Свою магистерскую диссертацию в свой первый год работы я сделал на моделировании рынков электроэнергии, это один из трех примеров, о которых я расскажу позднее.
В последние годы работы в Росатоме мы стали создавать веб-интерфейс для наших моделей. То есть изначально мы в Excel что-то строили и презентации рисовали, а потом решили, что будет удобно руководству и другим аналитикам показывать модель, в которой можно понажимать кнопки, что-то поменять в параметрах и посмотреть, что изменится. Там у меня был первый опыт постановки задач разработчикам, мы наняли IT-подрядчика, который делал веб-интерфейс.
После этого я перешёл в Аналитический центр, где начал заниматься анализом данных и как раз развил свой опыт постановки задач разработчикам на примере Единого хранилища данных и на других ИТ-системах. И в Росатоме, и в Аналитическом центре были основные проекты и всегда были такие мини проекты. Например, нужно анализ провести за несколько дней и какие-то выводы сделать, показать руководству, представить цифры. Примеры кейсов я буду по ходу рассказывать, давайте перейдем к качествам хорошего аналитика.

Качества аналитика
Первое, самое важное, это критическое мышление. Это умение ставить все под сомнение, умение формулировать гипотезы, проверять их. Нужно в каком-то смысле иметь свою голову на плечах, не принимать ничего на веру, а думать, почему именно так. Не потому, что принято так делать, а подумать, действительно ли так нужно. Это, на мой взгляд, самое важное качество аналитика, и возможно, вообще любого человека.
Второй момент — это умение работать с цифрами, то есть если вы аналитик, вам без цифр никуда. Вы должны уметь работать как с маленькой табличкой, например в 10-20 строк, так и с большими, в десятки тысяч, и с огромными таблицами в десятки миллионов строк. Соответственно про методы, которые для этого нужны, я расскажу на следующем слайде.
И третье качество — интерес к задаче. Если вам задача не интересна, Вы не понимаете, зачем она делается, Вы навряд ли будете с упорством ее исследовать, пытаться что-то понять. Здесь еще я бы такой тезис привел – в аналитике важна честность перед самим собой. То есть вы должны верить в результат вашей работы, в ваши выводы, в тот анализ, который вы делаете, потому что, если вы сами не верите в ту аналитику, в те выводы, аргументы, которые вы приводите, то, наверное, они не очень хорошие. Здесь приведу в пример Нассима Талеба, писателя и философа, о котором многие из вас, наверное, слышали. Мне нравятся его книги, в которых говорится, что всегда аналитик, эксперт должен нести ответственность за результат, чем-то рисковать. Могу привести пример про моделирование финансовых рынков. Многие строят прогнозы и мне всегда таких людей хочется спросить,
Вы спрогнозировали рынок, а готовы ли Вы поставить деньги на ваш прогноз или нет? Если нет, возможно, Вы сами не верите в свою модель.
Навыки аналитика
Первое и самое главное — это Excel. Самый простой инструмент, в то же время его можно бесконечно изучать и погружаться в него. Он позволяет легко поработать с цифрами, построить графики и сделать какие-то выводы. Еще важен VBA (Visual Basic for Applications) - язык программирования для среды Microsoft Office. Он помогает вам автоматизировать какие-то ваши рутинные задачи, рутинные процессы. В Excel очень много всего можно сделать формулами, но не все, и зачастую буквально десять строчек кода позволяют очень сильно упростить вашу жизнь. Здесь приведу пример — в Аналитическом центре мы в последнее время активно используем VBA для автоматизации построения аналитической отчетности, для автоматизации построения презентаций. У нас данные подтягиваются в Excel, а дальше макросы перестраивают графики, автоматически переносят их в презентацию и обновляют текстовые подписи и даже некоторые картинки. Всё это сохраняется в PDF и уходит руководству в ежедневном или еженедельном режиме. У Excel есть ограничение на объем данных, там помещается миллион строк, но даже когда у вас уже несколько сотен тысяч строк, он начинает подтормаживать.
Чтобы поработать с большими объемами данных, самый простой и распространенный способ — это SQL, база данных. У него есть два плюса, во-первых, вы как правило обращаетесь к серверу, который мощный, обычно от 64 Гигабайт оперативной памяти и 10-20 ядер процессора, и вы можете сделать какие-то расчеты, которые на локальной машине делать слишком долго или просто вы не сможете посчитать. Второй плюс - зачастую данные, которые вам нужно проанализировать, уже изначально хранятся в каких-то системах в формате базы данных. Поэтому вы просто подключаетесь и работаете с данными напрямую. Если вы не умеете работать с SQL, вам как правило нужно обращаться к разработчикам, просить сделать какие-то выгрузки, и здесь вы тратите время на итерации. То есть, когда я сам пишу SQL-запросы, у меня есть гипотеза, как данные устроены, я проверил и посмотрел. Ага, не так - нужен другой отчет, сразу переделал запрос и посмотрел. Если я ставлю ТЗ разработчику, даже простое, и я отдал его ему, он взял, понял, через какое-то время с учетом своей загрузки мне выдал результат. Я посмотрел – не подходит, нужно править ТЗ, и снова тратится время на итерации. А так, самостоятельно используя SQL, вы можете гораздо быстрее и эффективнее работать с данными.
Следующая тема – это Python. На самом деле, подойдет и R, и любой другой язык программирования, Python я указал, потому что мне кажется, у него больше библиотек под абсолютно разные задачи. Не только аналитические и исследовательские, но и, например, удобно поработать с файлами. В своё время мне нужно было из нескольких сотен PDF файлов вытащить конкретные страницы. Cкачав библиотеку и быстро в ней разобравшись, я решил задачу буквально за полчаса. Python часто помогает автоматизировать какие-то рутинные вещи. Например, мы довольно быстро, буквально 20-30 строчек кода, настроили проверку почты. Скрипт проверяет, пришли ли нам новые данные, если да, то забирает их, вставляет в Excel, запускает наши макросы, формируется презентация в формате PDF и отправляется в автоматическом режиме. Это работает без нашего участия, мы просто следим, чтобы всё работало, и это позволяет нам гибко что-то менять. Нам не нужны разработчики, чтобы автоматизировать эту отчетность.
В чате кто-то спросил про Power BI. Мы сейчас пробуем использовать различные BI-инструменты, но, на мой взгляд, они не очень гибкие. В презентациях и в Excel у вас гораздо больше гибкости. Вы можете произвольно расположить элементы и настроить шрифты, а это очень важно при представлении результатов руководству. Без BI это гораздо проще сделать.
В работе аналитика 90% составляет сбор и обработка данных
Самое первое, что вам нужно сделать, это найти источники информации. В пандемические времена мы стали работать с данными по коронавирусу. В самом начале оказалось не очень тривиальной задачей просто собрать исторические данные по дням, по регионам. Все ссылаются на данные Роспотребнадзора, но у него на сайте таких данных нет, нельзя скачать ретроспективу. Соответственно, нужно искать, откуда их можно скачать. Еще для нас в Москве важно знать не страновую статистику, а сравнивать Москву с другими городами, какая динамика по вирусу у них. Это тоже нетривиальная задача, нужно поискать отдельные города и оценить качество этих данных. Это первый этап.
Второй этап – из этих источников суметь собрать информацию. У вас может лежать куча вордов, PDF-файлов, нужно их скачать, и тут может Python прийти на помощь, какая-то автоматизация. Плюс еще пример – данные по вирусу, вы, наверное, слышали, что их Университет Джонса Хопкинса публикует. У них есть выложенный архив на GitHub и все данные по странам находятся в одном файле, который можно автоматически подключить в Excel для регулярного обновления. Но, например, регионы внутри стран и города, что нам в Москве особенно интересно, выкладываются каждый день в отдельном файле. И вот чтобы собрать сначала эту статистику, надо скачать несколько сотен файлов, вручную это очень долго, здесь как раз Python приходит на помощь, или на VBA можно, в Excel настроить. Плюс еще иногда нам приходится парсить данные, у нас был проект, мы парсили сайты по недвижимости, чтобы понять динамику цен предложений в Москве, тоже как раз с Python начали активно работать, чтобы собрать эти данные.
Третий момент – очистка и подготовка данных. Вы уже нашли источник, скачали все, куда-то сложили, в нормальную табличку, в базу данных. Вам нужно эти данные очистить и подготовить. Два примера: с той же статистикой по коронавирусу, например, когда строим ряд по дням, видим, что какие-то недели выбиваются, то есть три дня не было заражений, а потом на третий день заражений в три раза больше, чем в среднем за день. Понятно, как-то они перераспределили. Потом есть вещи, на которые у нас до сих пор нет однозначного ответа, что с ними нужно делать. По Мадриду статистика пересматривалась, по смертям от коронавируса, то есть они каждый день публиковали допустим 10-20 смертей, а потом в последний день месяца сказали, у нас минус 300 смертей. И вот что с этим делать, нельзя это как готовый ряд использовать, то есть либо вообще убрать- эти выбросы, либо перераспределить, тут уже разные задачи. И на примере с работой с данными по предложениям продажи недвижимости, квартир в Москве, мы смотрели, когда парсили объявления, что есть объявления с очень большой ценой, на которую смотришь, как будто человек вбил номер телефона вместо цены, перепутал поле. И это сразу среднюю цену увеличивает. Плюс тут нужно критически подойти, понять, какое отсечение поставить. Понятно, что есть средние цены на квартиру, но и есть очень дорогие квартиры, как понять, какие квартиры могут быть дорогими, а где точно ошибка? Поэтому всегда это процесс, к которому надо вдумчиво подойти, где можно – автоматизировать его, где не удается автоматизировать - руками распределить, глазами посмотреть.
Четвертый этап, который в основном и подразумевают под работой аналитика – это анализ и выводы. Собрали данные, построили графики, на них смотрите и пытаетесь какие-то умозаключения сделать или модели построить. На самом деле, в моей практике модели редко кому нужны, часто просто смотрят на графики, и уже из них все понятно, не нужно коэффициент корреляции считать и т.д. Этого достаточно, чтобы какие-то выводы делать.
Пятый этап, на который приходится тратить довольно много времени – правильное оформление результатов анализа. Если вы их непонятно или сложно представляете, не можете донести мысль, то это может загубить всю работу, вас просто не поймут. Поэтому здесь важно подойти, подумать, может на каких-то ваших коллегах или людях со стороны протестировать. А понятно ли, что вы здесь изложили и сделали? Чтобы работа не была слишком научной и никому не понятной.
Даже в Data Science построение и настройка моделей занимает лишь малую часть всех ресурсов
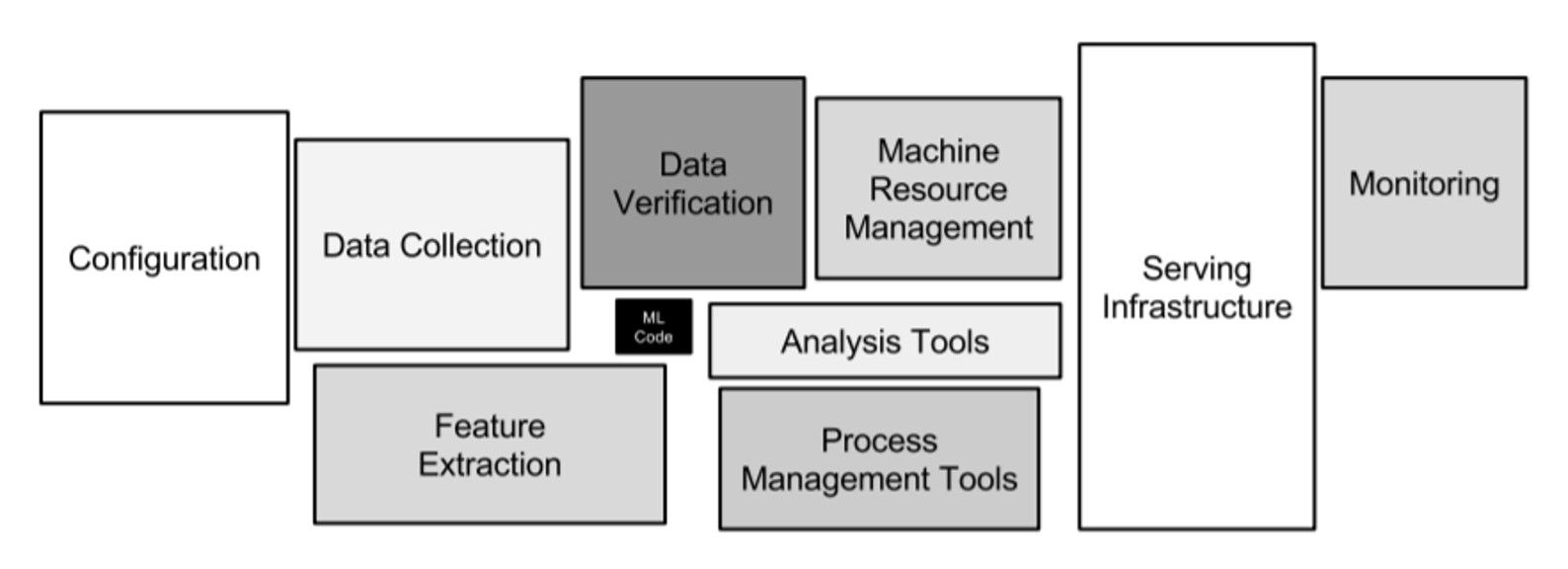
Хотел привести пример про Data Science и Big Data, картинку взял из курса по Big Data, который в своё время прослушал. На ней квадратиками отражены части процесса использования результатов машинного обучения. Черный квадратик, ML Code, это как раз сама модель машинного обучения, она занимает не так много ресурсов. То есть один Data Scientist что-то делает, тестирует разные модели, а вокруг этого куча инфраструктуры, куча людей, которые проверяют данные, инженеров, которые подготавливают и настраивают сервера и так далее. Это надо понимать и правильно оценивать. Зачастую важнее правильно подготовить и очистить данные, чем какую-то модель построить. И плюс зачастую модели машинного обучения на больших данных работают и окупаются только в больших компаниях, потому что, чем сложнее вы делаете модель, тем за меньшие доли процента точности вы боретесь. И вот чтобы доли процента точности окупили всю вот эту разработку, это должна быть большая компания с большими оборотами. Тогда инвестиции в сложное машинное обучение позволят эту сложность, эти доли процента точности, окупить.
Единое хранилище данных
Следующее – про проект, которым я занимался. Система называется Единое хранилище данных. У нас изначально стояла задача, как удобно поработать с социально-экономической статистикой. Пример. Для большинства найти заработную плату на сайте Росстата — это нетривиальная задача. Надо поискать в каких-то сборниках, в разных местах разное отображение. В поиске вобьете — не факт, что найдете сразу нужный раздел. Мы работали как с Росстатом, так и с Мосгорстатом, этому проекту семь лет, я как раз в 2014 году пришел в Аналитический Центр. У нас была внутри Департамента экономики Москвы задача сделать систему, чтобы эксперты могли эту статистику удобно находить. Мы собрали туда данные Росстата и Мосгорстата, потом посмотрели, что у нас инструмент хороший получился, и мы стали добавлять данные из других источников, федеральных ведомств, часть из них представлены на экране. Поясню в чём польза системы. Данные бывают в разном виде, ворд, PDF, мы от Мосгорстата обрабатываем иногда сборник на 300 страниц в ворде, и там несколько сотен показателей. У нас настроены полуавтоматические инструменты, которые позволяют нашим сотрудникам за несколько часов эти данные обработать и загрузить в систему, чтобы пользователь уже мог поработать с форматом куба данных – перетаскивать разрезы, строки и столбцы местами менять, фильтровать таблицы. Есть другой пример - сайт Налоговой службы. Там в принципе все хорошо структурировано, выложено в Excel, но там какая проблема - одна экселька за один период. Чтобы за три года собрать месячный ряд, вам нужно скачать 36 файлов и объединить их, еще в каждом файл может быть 10 и более листов. И при этом они могут быть немного разные, то есть менялись справочники, статьи доходов, расходов, что-то еще, а вам нужно, чтобы сопоставимый ряд был. Вы можете эту работу проделать, но потратите на это несколько часов времени. Наша команда, наши аналитики, сотрудники проделывают эту работу и собирают все в одном месте, чтобы было можно посмотреть и не тратить время. Более того, если вы зарегистрировались в системе, можете добавить себе эти показатели на рабочий стол, подписаться на обновления, и вам будут на почту приходить уведомления о том, что такой-то показатель обновился у Налоговой, зашли, взяли с ЕХД или даже с сайта Налоговой. Ещё нашу систему всегда можно использовать в случае, если вы не знаете, где есть нужные показатели. Вбили в поиск, и вы сразу видите, в каких источниках эти данные могут быть. Мы стараемся загружать как можно больше данных, но в силу объема не всё можем забирать. Может, какой-то показатель у нас нашли и думаете, а есть ли у этого источника что-то подробнее, и можете к этому источнику на сайт перейти и посмотреть. Ещё зачастую мы подкладываем под показатели, если есть, исходные ворды и PDF. Мы их в справочные документы к показателям привязываем, чтобы пользователь мог посмотреть, откуда мы взяли эти цифры.
Адрес системы www.ehd.moscow
ehd-support@develop.mos.ru - адрес нашей технической поддержки, которую непосредственна моя команда ведет, можете туда написать, и мы предоставим вам доступ, или ответим, если есть вопросы по работе с системой, по методологии расчета показателей. Более того, система доступна даже без пароля, можете сейчас зайти, посмотреть интерфейс. В разделе «Помощь» есть краткие видеоуроки, которые вам позволят весь инструментарий изучить. Мы систему делали под себя как аналитиков, чтобы нам было удобно ей пользоваться, поэтому у нас там довольно хороший графический инструментарий, можно на картах данные отобразить, хотя это достаточно распространенная вещь. Мы считаем, что у нас user-friendly интерфейс получилось сделать.

Перейдем к примерам из моей практики.
Пример 1. Прогнозирование спроса на электроэнергию

Пример старый, я снизу написал, что делал это в Eviews в 2010 году. Даже в 2009 начинал модель делать, несколько периодов строили прогнозы. Была проблема, кризис 2009 года, падение спроса на электроэнергию, важно понять, что будет в будущем. Я начну немного с конца - какую модель строил в начале 2010 года, когда пошло некое восстановление. Здесь 4 графика, представлены факторы энергопотребления. Использовалась самая простая линейная множественная регрессия, никаких сложных методов. Задача была – просто разложить и оценить влияние факторов и посмотреть, как они повлияли на текущие результаты. А также очистить сезонный характер спроса на электроэнергию от факторов и выделить тренд, который мы считали экономикой, как он развивается. Тут видно, что это некая синусоида потребления энергии, и основной фактор, который позволил ее убрать, это сочетание синус-косинус, долгота светового дня и годовые колебания температуры. То есть день становится длиннее и теплее, мы меньше тратим электроэнергии на освещение и на отопление, так как где-то отопление идет за счет электричества. Мы находились тогда в марте 2010 года, на нижнем левом графике это как раз та точка, из которой расходятся три луча. Мы очистили, посмотрели, использовали dummy переменные, чтобы изломы тренда оценить, и поняли, что мы находимся в данной точке.
Вопрос, что делать с прогнозом, каким будет тренд? Его сложно предсказать. Самый простой прогноз – все будет, как было. Вообще про прогнозирование есть такая хорошая цитата, которая мне нравится, что
прогнозирование похоже на попытку вести машину, глядя в зеркало заднего вида. То есть вы видите только то, что произошло, а будет дальше прямая или поворот, эконометрические и вообще статистические методы не могут сказать, они опираются на прошлое
Здесь мы просто предположение ввели, давайте три варианта рассмотрим. Либо будет расти как росло, либо вдруг не будет никакого роста и будет горизонтальная линия, либо будет такое же падение, как был кусочек падения в конце 2008 - начале 2009 года. И соответственно построили разброс. Получилось, что рост будет от 2 до 6 процентов. Мы сказали, что падение маловероятно, что спрос будет расти на 3,8-6%, скорее всего (как говорится, истина лежит где-то посередине), наш прогноз – 5%.
Тогда мы смотрели, что в журналах, в Коммерсанте или Эксперте, про потребление электроэнергии многие эксперты говорили, что весь рост вызван тем, что была холодная зима. Действительно тогда была холодная зима. Вопрос в том, сколько миллиардов Квт*ч из этого потребления пришлось на фактор холодной зимы? Я на правом нижнем графике показал это влияние. Влияние холодной зимы января дало 3 миллиарда Квт*ч, на уровне потребления порядка 80-100 миллиардов оно не очень большое. Мы тем самым показали, что да, холодная зима влияет, за счет нее выше спрос, но не настолько выше, и без этого был рост. Это один из способов применения эконометрики, но честно скажу, я ее единственный раз в жизни использовал в своей работе. Возможно, это было связано с тем, что я еще учился в магистратуре и мне хотелось применить эконометрику.
По поводу прогнозирования: я эту модель начинал делать в 2009 году, как раз когда мы находились в нижней точке тренда, и было непонятно, что делать. Если тренд продлевать вниз, то падение 2009 года получалось почти 20%. Если вверх, то вопрос, насколько его загнуть, статистика не говорит этого. Мой руководитель тогда посмотрел, а он всегда неплохо прогнозировал, глядя на графики, смотрел на них и прикидывал. Он говорит: “Заложи такой тренд, чтобы по 2009 году было падение 4,5%.” Я заложил, развернул тренд и построил, как по месяцам будет выглядеть, если падение по году составит 4,5%. Потом я в начале 2010 года посмотрел, когда данные вышли, а падение по году получилось 4,4%. То есть очень близко, так сказать, экспертный опыт. Про эту модель все, это что касается эконометрики.
Пример 2. Модель рынка электроэнергии
Здесь мы активно использовали так называемую математическую экономику. Модель реализована в Matlab и я на этой модели сделал свою магистерскую диссертацию. Это был очень хороший момент, я и на работе делал работу, и магистерскую диссертацию. Она и там, и там пригодилась. Тогда в стране существовало 400 электростанций, и к 2020 году планировалось построить еще 200. Но это планирование 2007-2008 годов, а кризис 2009 года сильно снизил потребление, было понятно, что к 2020 году мы на заложенный уровень потребления электроэнергии скорее всего не выйдем. Поэтому нужно решить, какие из этих 200 станций строить. Для Росатома задача была в том, чтобы понять, какие из запланированных блоков АЭС нужно построить, а какие – нет. Какие будут загружены, а какие – нет.
Ситуацию усложняло то, что модели рынка электроэнергии постоянно менялись, менялись правила, и мы не могли заранее предположить, а что будет в 2020 году с правилами рынка. Но мы приняли такую аксиому, взяли на веру, сказали, что модель рынка электроэнергии, наверное, должна приводить к наиболее эффективной загрузке электростанций, поэтому мы просто построим модель эффективной загрузки. И это звучало как “поиск минимума совокупных затрат”. Такую задачу мы решали с помощью целочисленного линейного программирования. Линейное программирование – это поиск экстремума линейной функции при линейных ограничениях. На самом деле, вся экономика – поиск экстремума при ограничениях. У нас есть безграничные желания и потребности и ограниченные возможности. И мы пытаемся наиболее эффективным образом их удовлетворить. Почему целочисленное линейное программирование: мы могли электростанцию целиком построить либо не построить вообще, не могли построить половину. Мы или несем инвестиции как затраты на строительство, или не несем. Плюс у нас были различные сценарии цен на энергоносители, что будет с газом, если газ дорогой, тогда газовые станции менее конкуренты. Что будет нефтью, с углем? Хотя на нефти совсем мало электростанций, на мазуте, это наиболее дорогие, так называемые пиковые мощности.
Плюс той ситуации с точки зрения данных был в том, что в схеме были запланированы 200 станций, было написано, где они должны быть построены, какая их мощность, расход топлива на Квт*ч электроэнергии. Вся информация была, довольно легко было её из документов вытащить. И мы могли всё посчитать, вот такую модель сделать. Получалась своего рода транспортная задача, поскольку вся страна делилась на 30 зон свободного перетока. Считалось, что если внутри зоны мы можем построить станцию, то всех потребителей этой зоны мы можем удовлетворить без ограничений. А если нам нужно передать электроэнергию из одной зоны в другую, то там мы ограничены мощностью линий электропередач. Соответственно эти ограничения и были в задаче линейного программирования.
Мы решили эту задачу и показали, вот эти станции в таких-то сценариях будут загружены, а в таких-то нет. Это было как аналитическое мнение, как записка для руководства. Были и другие мнения в Росатоме, например, нужно строить электростанции там, где уже есть существующие энергоблоки, так как там дороги подведены, и инфраструктура есть, не важно, электроэнергию как-то передадут. Если говорить про критическое мышление, интерес к задаче и честность. Здесь, конечно, было много неизвестных (прогноз цен на энергоносители на 2020 год, прогноз спроса на электроэнергию, от этого сильно всё зависит), а решение о строительстве нужно принимать уже сейчас. Газовые станции 3 года строятся, атомные – 5 лет. И более того, с точки зрения самой задачи, у нас были ограничения ЛЭП как жестко заданные. С точки зрения общей эффективности можно было бы решить эту задачу, поняв, а где нужно построить, расширить узкие места, добавить линии электропередач с учетом затрат на их строительство.
В чате пишут, “очень тяжело без инженерных знаний построить что-то близкое к реальной жизни”. На самом деле, мы строили технико-экономические модели жизненного цикла атомных станций: сколько ресурсов нужно, чтобы их построить, поддерживать и т.д. У проектных институтов была задача – придумать проектные решения, которые удешевят стоимость строительства и повысят эффективность. А мы оценивали эти решения. И там довольно глубоко приходилось погружаться. Во-первых, были эксперты и консультанты. Во-вторых, я сам проектную документацию АЭС читал, разбирался, как здание построено, что куда идет, чтобы понять, в чем экономический смысл проектного решения. Инженерных знаний у коллег хватало, просто вообще в жизни много неопределенностей и не все можно предсказать.
Пример 3. Анализ платежей за ЖКУ в Москве
Третий пример – из текущей практики, данные, с которыми мы работаем из месяца в месяц, обрабатываем их и периодически какой-то анализ проводим по запросам. Это анализ платежей за жилищно-коммунальные услуги в Москве. Кто в Москве живет, знает, вам каждый месяц в почтовый ящик опускают единый платежный документ, ЕПД, где указано, сколько услуг, сколько воды, тепла вы потребили и должны оплатить за месяц. По объему данных – мы получаем каждый месяц 4 миллиона платежек, то есть это 4 миллиона квартир; мы получаем данные от Единого Информационного Расчетного Центра (ЕИРЦ), он охватывает не все квартиры, но, по нашим оценкам, 80-90% квартир Москвы. В каждой такой платежке до 10 услуг, итого 40 млн записей в месяц или 500 млн записей в год нам выгружают в базу. У нас есть ретроспективные данные за 5 лет, то есть больше 2 миллиардов записей. Это пример того, почему нужно уметь работать с SQL, потому что при помощи Python вы можете прочитать эти файлы, но на локальной машине будет сложно и долго с ними работать.
Когда мы эти данные получили, мы стали на них смотреть. И важно критически отнестись к данным и сделать какие-то шаги по очистке. Приведу некоторые из них. Самое первое, что в голову приходит – посчитать средний платеж. Возьмем суммарный платеж и на 4 миллиона квартир поделим. Стали смотреть в деталях – а важно именно самим в данных ковыряться, если вы разработчикам-технарям такое ТЗ поставите, они вам так и посчитают – и увидели, что у миллиона квартир есть только одна услуга, капремонт. То есть капремонт начислялся через ЕИРЦ, а остальные услуги как-то по-другому, может, ТСЖ начисляло или управляющая компания как-то счета выставляла. Мы поняли, что надо очищать. Посмотрели, сколько у нас полных платежек, вероятно, в Москве не может быть квартир, где нет холодной воды, или нет канализации, отопления. Смотрели, очищали. У нас были сложные с точки зрения логики шаги, там не было никакой сложной математики, но с точки зрения логики и объяснения – а нам приходилось показывать и объяснять – не всегда было просто кратко и понятным языком рассказать, почему мы эти данные очищаем. Мы очищали данные, у нас получалось 2-2,5 миллиона квартир, на которых мы уже могли делать какое-то моделирование.
Моделирование тоже было простое. Департамент экономики принимает тарифы на ЖКУ и ему важно понимать, как распределится прирост платежей, у скольких людей прирост будет выше допустимых значений, у скольких – в пределах нормы. Плюс, на этих данных можно много интересной информации посчитать, например, к нам иногда обращаются с просьбой определить количество так называемых инвестиционных квартир, то есть в которых никто не живет, не потребляет ничего. То есть купили, сделали ремонт, уехали, не сдают, ничего. Плюс, коллеги косвенным образом пытаются выявлять факты незадекларированной сдачи в аренду, где никто не прописан, а воду потребляют. Там используют разные алгоритмы. Этим у нас занимается другая организация, мы просто с ними данными делимся.
Еще по шагам очистки: нам был важен признак наличия общедомового прибора учета по теплу. То есть если в доме нет счетчика тепла в подвале, то им выставляется по нормативу на квартиру, 16 МКал на квадратный метр. У нас признака явного нет в базе, но мы видим реальное потребление. Логично сказать, что если у дома среднее потребление 16 МКал на квадратный метр, то, значит, у него нет счетчика. Если не 16, то есть счетчик. Мы смотрим и почему-то 95% квартир в доме имеют именно 16, а другие – нет. Как такое может быть? Придумали такой эвристический алгоритм, что если 90% квартир имеют 16, то будем считать, что там есть счетчик тепла. Причем эти 16 тоже надо считать с учетом погрешности, потому что если мы потребление делим на площадь, то не 16 может из-за округления получаться. Целый вагон и маленькая тележка тонкостей при такой обработке и расчете.
Взгляд на образование
Часто спрашивают, я не знаю, куда пойти учиться, куда лучше идти? На какой факультет и какую специализацию? Мне нравится мысль про то, что нужно идти туда, где сложнее. Я на самом деле в определенной степени сам этим руководствовался, когда шел на МатМетоды, не понимал, куда я точно хочу. Но знал, там много математики, наверное, там будет интересно, сложно и т.д. Это первый тезис.
Второй тезис – пытайтесь изучать сами. Не пытайтесь просто слушать и понимать, что вам рассказывают. Пытайтесь сделать сами и потом задавать вопросы, если что-то не получается. У нас на некоторых предметах в бакалавриате часто семинаристы очень здорово делали - они высылали задачи и просили заранее прорешать дома, попробовать решить. Мы приходили на семинар и уже задавали вопросы, мне это очень помогало. Когда вы пытаетесь сделать сами, эффективность вашего обучения на порядок поднимается, чем если вы эту задачу первый раз видите на семинаре, и вам просто рассказывают, как ее решать. Вы не успеваете нормально подумать, как ее решить, вам просто рассказывают.
Третий тезис – мир меняется, нужно постоянно учиться, и мне, и вам. Постоянно появляются новые технологии, подходы, всегда нужно что-то изучать. Про себя могу сказать, что даже Excel я уже после магистратуры нормально изучил, SQL тоже. SQL я начал изучать, когда у меня появилась потребность работать с десятками и сотнями миллионов записей, до этого практически с ним не работал. Python тоже изучил специально для парсинга и автоматизации. Поэтому всегда новые методы придется учить, но это интересно.
Еще один тезис, цитату хотел привести, про обучение. Часто спрашивают, какие методы нужны и зачем. Я в свое время перед магистратурой МатМетодов сходил на день открытых дверей в РЭШ, и там один из выпускников в коридоре сказал:
У нас в стране все думают, что при покупке образования они покупают знания, а на самом деле они покупают диплом как индикацию того, что они смогли учиться в этом заведении. Раз они смогли этим сложным вещам научиться, значит, если нужно будет что-то другое, то они легко смогут разобраться и научиться.
И вообще высшее образование хорошо развивает критическое мышление, о котором я говорил в начале. Вышка среди первых вузов, где вы учитесь сложным вещам, пробуете в них разбираться. Это хорошо тренирует мозг и развивает ваши аналитические способности.
Еще по поводу специализации, какие выбрать навыки и так далее. Приведу такую картинку, буквально пару лет назад на Хабре статью прочитал, показалась очень полезной.

Очень сложно стать лучшим экономистом в мире, вы скорее всего им не станете, потому что вам нужно приложить очень много усилий. Здесь на левом графике, по-моему, Надаль изображен, теннисист. Чтобы стать лучшим теннисистом, нужно сильнее всех тренироваться и потратить много сил. Но чтобы войти в топ-10% лучших теннисистов мира, я не говорю про рейтинг, не в топ-10 рейтинга, а вообще в топ-10% среди всех людей, вам не так много усилий и удачи нужно, это достижимо. Вы просто можете поучиться и стать. А дальше вы можете еще по какому-то навыку быть хорошим специалистом, не лучшим. Но по сочетанию этих двух навыков, это правый график, вы станете одним из лучших в мире. Тоже могу привести статистический пример из своей практики, когда я в Вышку целенаправленно готовился, ходил на Факультет довузовской подготовки. Там у нас был рейтинг по итогам тестовых экзаменов, контрольных, и я занимал с 20 по 30 место. Было 4 контрольные в год, и я довольно стабильно занимал эти места. А в итоговом рейтинге я оказался на 12 месте, то есть я ни разу не занимал 12 место, но в то же время это сочетание 4 контрольных позволило мне стать лучше. Здесь такой же подход. Здесь такой пример, может, немного умозрительный, слишком фантастический, но допустим, вы хороший экономист, а еще вы хороший писатель, вы классно пишете, рассказываете. И вы можете стать лучшим в мире популяризатором экономики, потому что вы и экономику знаете, и пишете хорошо, и так далее. Советую держать это в голове.
Книги для погружения в аналитику
В конце я хотел несколько книг порекомендовать для погружения в аналитику. Сам недавно прочитал книжку “Много цифр: Анализ больших данных при помощи Excel”. Я в начале к названию скептически отнесся, что за Big Data в Excel? В Excel много данных не влезает. А там как раз на небольших реальных примерах показано, как модели машинного обучения можно сделать в Excel даже формулами без программирования. И показаны цели и задачи, для которых они нужны. Плюс там еще на довольно глубоком уровне показано использование Excel, там даже я, кто всю жизнь с ним работает, нашел какие-то новые и интересные вещи. Почитайте для погружения именно в аналитику данных, методы машинного обучения, эконометрику, чтобы понять, о чем это и где может применяться на практике.
Вторая книжка по Python, “Изучаем программирование на Python”. Я несколько книг по Python прочитал, на самом деле, мне просто самому иногда интереснее и проще, полезнее прочитать книгу, чем читать какие-то отдельные статьи. Более целостный взгляд возникает, а потом уже можно идти в конкретном направлении, по нему что-то гуглить, StackOverflow читать и так далее. Это серия Head First издательства O’Reilly, и у них есть разные книги, и по SQL, и по языкам программирования, и еще по каким-то наукам. Они ориентируются на то, чтобы очень понятно и доступно информация сама ложилась в мозг. Для тех, кто боится программирования, мне кажется, эта книга самая простая и самая полезная будет, посмотрите еще книги из этой серии.
И третья, тоже в последние годы прочитал книгу по визуализации, “Говори на языке диаграмм”. Автор, Джин Желязны, он директор по визуализации в McKinsey, просто описывает примеры, как люди строят графики и как надо, почему какие-то графики непонятны. Я для себя тоже какие-то моменты подчеркнул. Самый простой пример – когда я рисовал график динамики продаж, то и заголовок графика всегда ставил “Динамика продаж”. А автор пишет, что
нужно не “Динамика продаж” график называть, а, например, “Продажи в феврале выросли на 50%”, то есть сразу человеку говорить, на что нужно смотреть на графике.
В книге еще много разных вещей по расположению элементов, которые будут полезны для аналитиков.