

Как отличить помидор от философии: в школе лингвистики прошел мастер-класс по дистрибутивной семантике
В минувший понедельник научный сотрудник Универитета Осло и приглашенный преподаватель школы лингвистики Андрей Кутузов провел мастер-класс по моделям дистрибутивной семантики.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Дистрибутивная семантика — один из трендов современной компьютерной лингвистики, так как она позволяет компьютерам до определенной степени приблизиться к пониманию значений слов. В своей лекции Андрей Кутузов рассказал о том, как устроены дистрибутивные семантические модели и каким образом возможно научить машину понимать, что "помидор" и "томат" — это одно и то же, а “философия” и “томат” — нечто совсем разное.
Презентация Андрея Кутузова по дистрибутивной семантике (PDF, 1.89 Мб)
Основная идея состоит в том, что смысл слова можно составить из слов, стоящих рядом (know a word by its company). Значения слов представляются в виде вектора, числа в этом векторе соответствуют частотам встречаемости слова с другими словами. Если слова часто появляются в одном контексте, то, вероятно, у них похожие значения, а значит, в нашем векторном представлении у них похожие вектора. Дистрибутивные модели нужно обучать на больших корпусах текстов, чтобы получить как можно больше информации о встречаемости слов.
Как только получена обученная дистрибутивная модель, перед исследователями открываются широкие возможности. Например, с помощью модели компьютеры могут выполнять алгебраические операции над смыслами: "мужчина - женщина = король - ?" - какое слово имеет такое же отношение к слову "король", как слово "женщина" к слову "мужчина"? До появления дистрибутивных моделей было очень сложно написать программу, которая вычисляет такое семантическое уравнение и выдает ответ “королева”.
Модели можно обучать на разных текстах, тем самым сообщая ей информацию о разных словах. Так, модель обученная на корпусе новостей, может отвечать на вопросы о политике или происшествиях. К примеру, если мы знаем, какие есть террористические группировки в Нигерии, и хотим узнать о группировках в Индии, то можно нашей модели дать такое уравнение: "Нигерия - Боко Харам = Индия - ?".
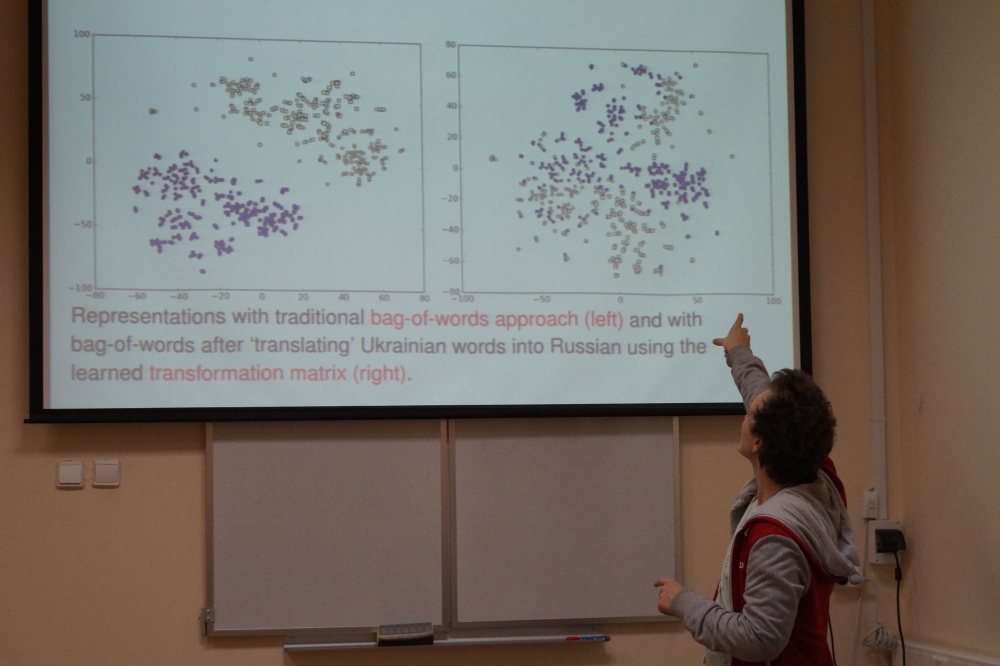
С помощью дистрибутивной семантики легко и быстро решается множество проблем: снятие семантической неоднозначности, тематическая кластеризация, генерация тезаурусов, поиск синонимов, антонимов, гиперонимов и многое другое. В качестве примера Андрей рассказал о своём недавнем исследовании, посвященном проблеме обнаружения схожих по тематике документов на разных языках.
Презентация Андрея Кутузова о применении дистрибутивной семантики для выявления схожих текстов на русском и украинском языках (PDF, 877 Кб)
Андрей и его коллеги провели эксперимент на русских и украинских текстах и показали, как свести проблему кластеризации многоязыкового корпуса к проблеме кластеризации корпуса на одном языке, имея при этом большой корпус одного языка и совсем небольшой переводной словарь для пар языков. Исследование основано на идее, что вектора слов на разных языках можно напрямую переводить на другой язык: то есть можно так повернуть, растянуть или сжать вектор слова на русском языке, что получится вектор его перевода на украинский язык.
Ознакомиться с результатами исследования можно здесь.
Кутузов Андрей Борисович